The complete guide to multi-platform ecommerce marketing strategy
Your guide to ecommerce advertising best practices with Klaviyo
Summary: ecommerce advertising strategies for 2026
Each ecommerce advertising platform requires a unique approach: Facebook excels at customer testimonials and retargeting, Instagram drives product discovery and impulse purchases, TikTok demands authentic content that captures attention quickly, while Google and Amazon focus on high-intent traffic.
The key to success lies in strategically balancing multiple platforms while using zero- and first-party data to create more targeted, effective campaigns.
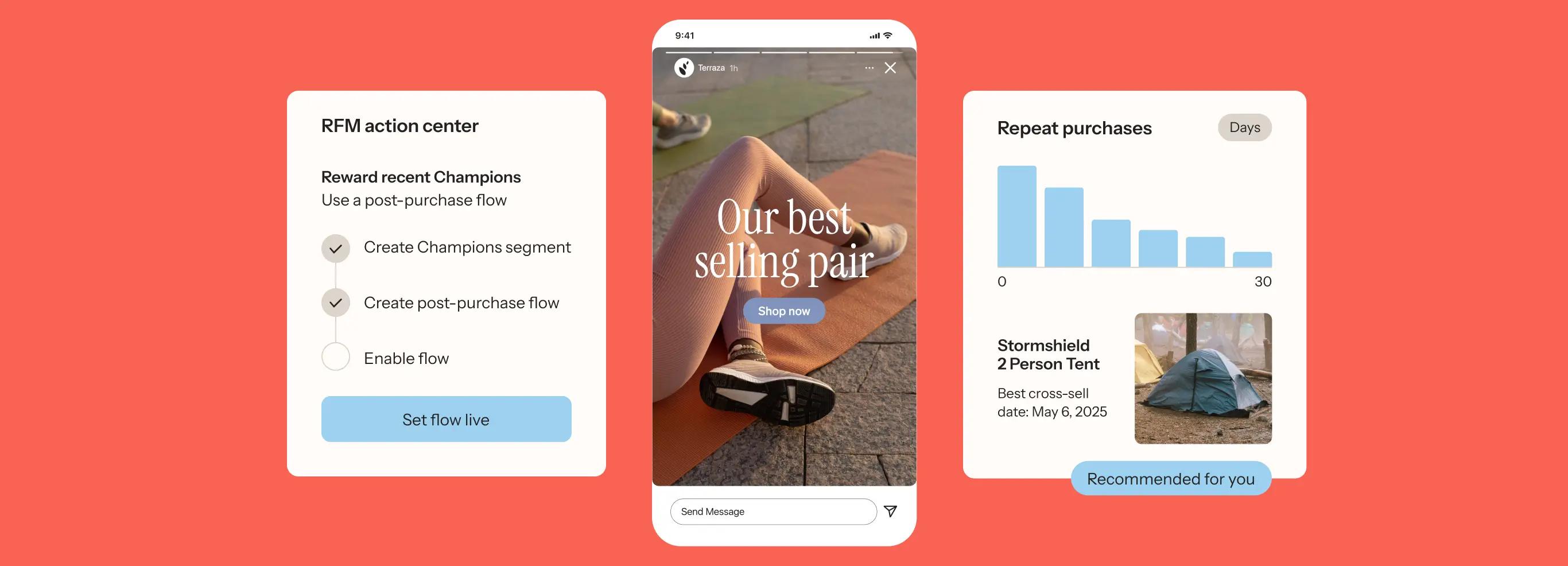
Ecommerce advertising has evolved far beyond simple product promotion. As customer acquisition costs climb and privacy changes reshape targeting capabilities, today’s most successful brands adopt a sophisticated mix of platforms, creative strategies, and zero- and first-party data to acquire and retain customers profitably.
This comprehensive guide breaks down proven strategies across 11 major advertising platforms, from Facebook and Instagram to other names like WhatsApp. With examples from real-life brands, you’ll learn exactly how top performers:
• Create effective advertising strategies for each major platform.
• Drive conversions through platform-specific best practices.
• Maximize performance on emerging advertising channels.
By connecting Klaviyo to these major ad platforms, you can create more targeted campaigns, find valuable lookalike audiences, and track performance across channels.

1. Facebook Ads: acquisition and retargeting
Facebook remains a cornerstone of ecommerce advertising, offering unmatched audience scale and sophisticated targeting capabilities. The platform excels at both cold traffic acquisition and retargeting campaigns, with particularly strong performance for brands selling products between $30 and $150.
When integrated with your marketing platform, Facebook’s advertising tools can turn zero- and first-party data into highly targeted audience segments.
Turn customer stories into compelling ad narratives
While customer testimonials work across platforms, they’re especially powerful on Facebook, where the algorithm favors content that drives meaningful interactions. The platform’s diverse ad formats—from carousel posts to video testimonials—let you showcase customer success stories in ways that feel native to users’ feeds.
Structure your testimonial ads to highlight specific product benefits that address common objections. For example, when running ads for a skincare product, you might:
• Lead with before/after customer photos.
• Include 2–3 specific quotes about results (“My dark spots faded in 3 weeks”).
• Add social proof elements like star ratings.
• Close with a clear product shot and price point.
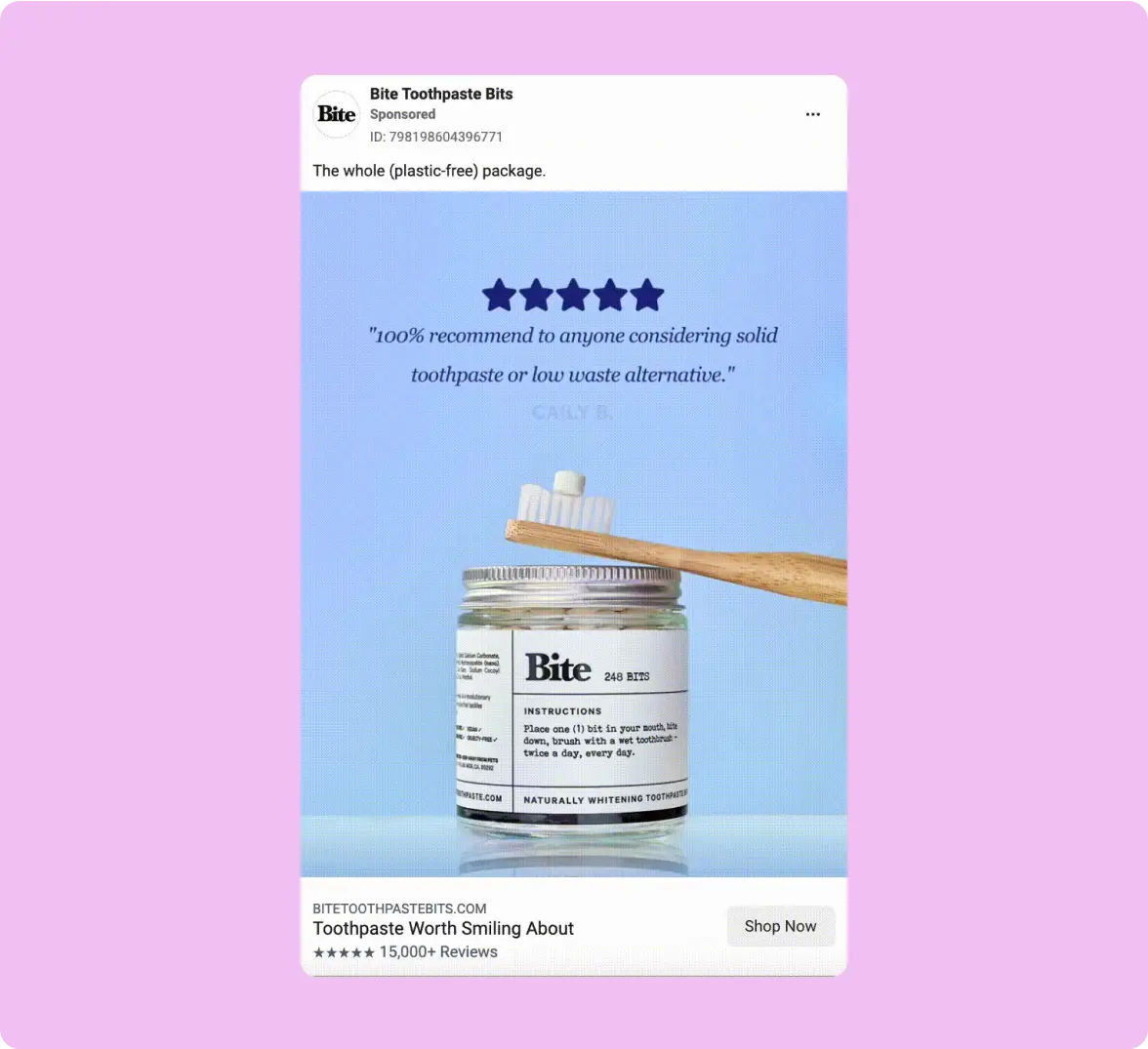
Bite, a brand that sells zero-waste toothpaste tablets, offers a great example of this. Their Facebook testimonial ad rotates through a series of customer reviews, with prominent 5-star visuals in both the testimonials and headlines, reinforcing the social proof.
This visual consistency helps build trust while maintaining viewer attention—exactly the type of authentic engagement that Facebook’s algorithm rewards.
Use zero- and first-party data to build high-intent audiences
Your existing customer data reveals valuable targeting insights. Connect your marketing platform to Facebook Ads to:
• Create lookalike audiences from your highest-value customer segments.
• Build retargeting campaigns based on browse and purchase history.
• Exclude existing customers from prospecting campaigns.
• Target customers who haven’t purchased in 60+ days with win-back offers. (Your win-back window could vary depending on your product type, but 60 days is a good target for consumable products.)
For example, you could target people who browsed your site’s winter collection but didn’t purchase, showing them ads on Facebook featuring your bestselling winter items along with limited-time free shipping offers.
Ecommerce advertising tip: “The higher your typical monthly advertising spend, the more frequently you should update ad creative,” says Ben Zettler, founder of Zettler Digital. “Be prepared to cycle in and test at least 3–5 new pieces of ad creative every week or so.”
From a metrics perspective, Zettler suggests monitoring cost per mille (also known as cost per thousand), cost per click, and cost per order to evaluate whether it’s time to update the creative or shut off an ad completely.
2. Instagram Ads: product discovery and impulse buys
Instagram’s advertising ecosystem differs somewhat from Facebook’s, despite their shared back end. The platform’s visual-first approach and dedicated shopping features make it ideal for product discovery and impulse purchases.
Showcase expert advice and content from real users
In this Instagram ad, dog dental powder company PetLab Co. combines the power of expert advice and user-generated content (UGC). The ad establishes credibility by featuring a veterinarian recommending the teeth cleaning product, then cuts to clips of real dogs and pet owner testimonials. The ad concludes by encouraging viewers to “Click below to shop now” to create urgency and make it easy for them to buy the product.
Here are a few ways to replicate this strategy:
• Shoot product photos in real-world contexts.
• Use Instagram’s product tagging in both organic and paid content.
• Match your ad aesthetic to your organic feed.
• Test both static and video formats with shopping overlays.
Design format-specific content that drives engagement
Each Instagram ad format requires a unique approach:
• Stories: Use vertical video with quick cuts and clear CTAs in the first 3 seconds.
• Reels: Create fast-paced product demonstrations under 15 seconds.
• Feed: Focus on scroll-stopping visuals with product benefits in the first line.
• Shop: Prioritize clean product shots with multiple angles.
For example, a skincare brand might run story ads showing a 10-second morning routine, reels demonstrating application techniques, and feed posts featuring before/after results—each optimized for its specific placement while maintaining consistent branding.
Ecommerce advertising tip: Zettler recommends matching your testing frequency and strategy to your ad spend. For budgets under $1,000/month, focus first on testing distinctly different creative approaches (like video vs. static images or entirely different videos, for instance) to identify what drives purchases. With larger budgets ($5,000+/month), you can refine high-performing formats by testing granular changes—like moving your CTA earlier in Story sequences or simplifying product showcases.
Aligning testing with ad spend prevents lower-budget campaigns from entering learning phases too frequently, while ensuring higher-budget campaigns stay optimized, Zettler says.
3. TikTok: authenticity and viral potential
On TikTok, the algorithm prioritizes content over followers, making every post a potential viral hit. With 120.5 million monthly active users in the US alone, mostly 18–34 years old, the platform’s rapid-fire format demands thumb-stopping content that captures attention in under 3 seconds.
Create content that matches platform energy
For TikTok ads to perform, they need to blend seamlessly with organic content while driving clear actions. Your TikTok ecommerce strategy needs certain key elements to succeed:
• Native content: Film vertically in 9:16 format with trending sounds.
• Quick hooks: Capture attention in the first few seconds.
• Authenticity: Raw, unpolished content often outperforms high production value.
For example, a skincare brand might show a split-screen “Get Ready With Me” ad where a real customer applies the product on one side while highlighting results on the other.
Build community through participatory content
TikTok’s Spark Ads format lets you amplify organic engagement through paid promotion. Here’s how to structure your ads for maximum participation.
Start with a “foundational ad” demonstrating your product—like a skincare brand showing a “3-step morning routine challenge.” Then, use Spark Ads to promote the best user responses to your original ad.
When viewers see both the original ad and real customers recreating it, they’re more likely to trust and engage with your brand, since the content feels more authentic than traditional product advertising.
This approach turns your ad spend into a catalyst for UGC, creating a self-reinforcing cycle where paid promotion drives organic engagement, which you can then amplify through additional Spark Ads.
4. Google Ads: high-intent traffic
Google Ads offers two distinct approaches to ecommerce advertising: Search and Shopping.
While Search Ads appear in text format based on keyword matches, Shopping Ads display product images, prices, and details directly in search results. Both formats tap into high-intent traffic—people actively searching for products like yours.
Ecommerce advertising tip: “Google Ads is primarily an intent-driven channel, and the value of zero-party data is in understanding the intent of a potential purchaser when they supply information directly to you,” Zettler explains. “When you use zero-party data in tandem with search data, you can create highly personalized ad experiences that typically convert better than standard targeting approaches.”
The same is true of first-party data, Zettler notes: “Information based on someone’s history from purchasing, site browsing, and more can also help inform their level of intent to purchase.”
Match search intent across the customer journey
Your Search Ad strategy needs to align with where customers are in their buying journey. For each product category, think about employing different strategies for each phase:
• Research phase: Target broad informational keywords.
• Comparison phase: Focus on specific product features and benefits.
• Purchase phase: Bid on exact product names and buying terms.
For example, if you sell running shoes, your keywords might progress from “best shoes for marathon training” (research) to “Nike Air Zoom vs. Brooks Ghost” (comparison) to “Nike Air Zoom Pegasus 39 price” (purchase).
Match each ad’s landing page and copy to the searcher’s intent at that stage.
Optimize product feeds for visibility and conversion
Your product feed determines how your items appear in Shopping Ads. Here are a few ways to maximize visibility:
• Front-load product titles with searchable terms.
• Include size, color, and material in product type fields.
• Add all relevant product categories.
• Update price and inventory data regularly.
• Use high-quality images against white backgrounds.
Consider a men’s winter coat listing as an example. Instead of “The North Face Jacket – Black”, structure the title as “Men’s North Face ThermoBall Eco Winter Puffer Jacket – Black.” This format includes essential search terms while maintaining readability.
5. Amazon: competitive product promotion
Amazon functions as both a marketplace and an advertising platform, offering Sponsored Products, Sponsored Brands, and Sponsored Display ads. While other platforms focus on discovery, Amazon captures customers with high purchase intent.
Though it’s not an owned channel, Amazon’s massive reach can significantly expand your brand’s exposure to new customers. The platform’s advertising tools let you promote products directly within search results and product detail pages, while brand registry unlocks additional promotional features.
Stand out in competitive product searches
Success on Amazon requires visibility in a sea of similar products. Here are a few ways to improve your position:
Target competitor Amazon Standard Identification Numbers (ASINs) with Sponsored Product ads.
• Use negative keywords to avoid wasting ad spend.
• Adjust bids based on placement performance.
• Test different match types for each keyword.
• Monitor your advertising cost of sale (ACoS).
In this Amazon search result for “tinned seafood”, seafood brand Fishwife’s products appear in a sponsored “Customers frequently viewed” section of Amazon.

Build brand presence beyond promotions
Your Amazon presence needs to extend beyond individual product listings. Here are a few ways to strengthen your brand:
• Create top-notch content with comparison charts and lifestyle imagery.
• Launch a Store page with curated product collections.
• Use Sponsored Brand Video ads to showcase product features.
• Maintain consistent brand voice across all content.
• Include detailed product information in bullet points.
Let’s say you sell kitchen appliances. Your Store page might feature seasonal recipe collections that incorporate multiple products, while your content shows size comparisons and highlights unique features through interactive images.
6. Pinterest: from discovery to decision to purchase
Unlike platforms focused on immediate engagement, Pinterest serves as a visual discovery engine where users plan future purchases. In fact, 85% of weekly active Pinterest users have made a purchase from their Pins.
“As a leading full-funnel solution that drives people from discovery to decision to purchase, all in one place, Pinterest continues to drive impact for brands—especially those offering luxury products,” writes Anthony DelPizzo, former product marketing lead at Klaviyo.
Why Pinterest works differently
With its robust visual search technology, Pinterest demands a different advertising approach. The platform combines search engine capabilities with social media features. A few key elements make it unique:
Visual discovery: Users can search using images instead of words.
Purchase planning: 96% of searches are unbranded, opening opportunities for new brands.
Content lifespan: Pins continue driving traffic for days on average, vs. mere hours on other platforms.
Creating effective Pinterest campaigns
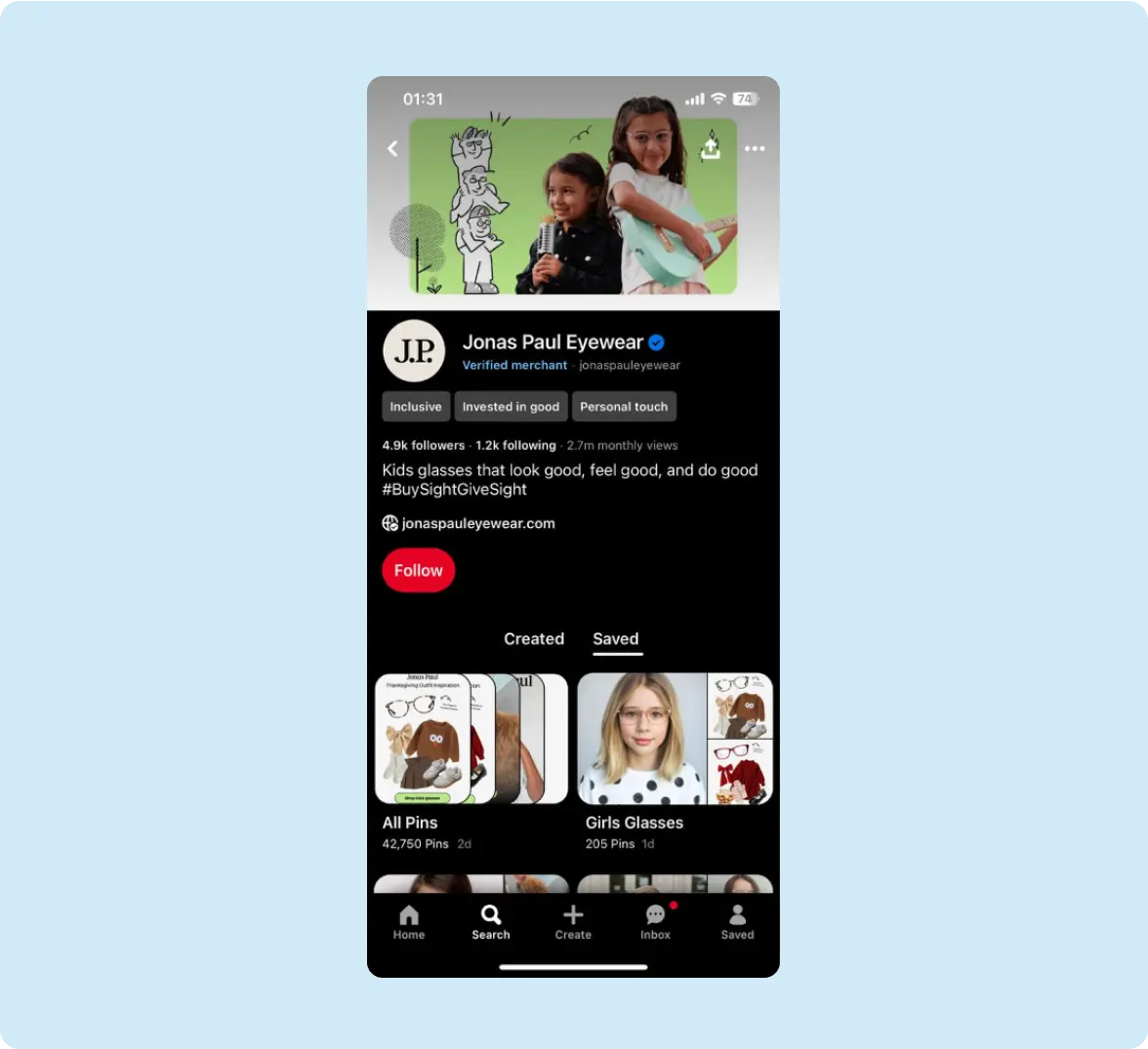
Here, get a sneak peek of how Jonas Paul Eyewear excels on Pinterest by creating content that aligns with how parents research and plan purchases. Their strategy includes:
• Multi-image Pins showing different styles on real kids
• Educational content about children’s eye health
• Seasonal eyewear recommendations
Here are a few ways to optimize your own Pinterest campaigns for purchases:
1. Diversify your Pin formats to maximize visibility and engagement. Each product deserves representation through standard Pins that showcase key details, Video Pins that demonstrate the item in use, and Collection Pins that group complementary products together. This variety helps capture attention at different stages of the discovery process.
2. Implement Rich Pins to display real-time pricing, craft detailed product descriptions that answer common questions, and ensure every Pin links directly to its corresponding product page for seamless check-out. Clear pricing and purchase information make the path to purchase smoother.
3. Take full advantage of Pinterest’s shopping-specific features to drive sales. Tag products in your organic Pins, connect your product catalog to power Shopping ads, and maintain an active Shop tab on your profile. These features turn casual browsers into buyers by reducing friction in the purchase journey.
7. WhatsApp: two-way communication
WhatsApp Business transforms direct messaging into a powerful sales channel through features like product catalogs, automated responses, and broadcast lists. Beyond traditional advertising, WhatsApp enables immediate two-way communication with customers.
The platform’s end-to-end encryption and verification badges build trust, while its API integration capabilities streamline customer service.
Creating engaging shopping experiences on WhatsApp
A cosmetics brand can turn WhatsApp into a digital storefront by designing interactive product discovery flows. Here’s an example of a message flow that could work for this:
• Customer: “I’m looking for a new moisturizer.”
• Auto-response: “Thanks for reaching out! Would you say your skin is: 1) Dry 2) Oily 3) Combination”
[Customer selects option]
• Auto-response: [Sends catalog of relevant products with descriptions and prices]
In WhatsApp, your brand can take a similar approach, setting up quick replies for common questions and using message templates to guide customers through their buying journey.
Your product catalog should include clear images, prices, and descriptions—all accessible within the chat interface.
Personalizing customer interactions
WhatsApp Business API lets you segment your broadcast lists based on previous purchases and browsing behavior. Create separate groups for:
• First-time buyers vs. repeat customers
• Product category preferences
• Purchase frequency
• AOV
Then, tailor your WhatsApp messaging accordingly. For instance, when launching a new line of sustainable packaging, you might send personalized announcements to customers who’ve previously bought eco-friendly products, complete with exclusive early-access codes and direct purchase links within the chat.
These targeted WhatsApp messages feel more like helpful updates than promotional broadcasts, maintaining the platform’s personal messaging feel while driving higher engagement and conversion rates.
8. Bonus platforms: Snapchat, LinkedIn, X, and Reddit
Snapchat: augmented shopping experiences
Snapchat’s AR capabilities create unique opportunities for product visualization. For ecommerce brands, this could translate into virtual try-ons and immersive product demonstrations.
Here are a few ideas for turning your products into interactive AR experiences on Snapchat:
• Beauty brands can create makeup try-on lenses.
• Furniture retailers can help users visualize items in their space.
• Fashion brands can offer virtual fitting rooms.
• Accessory brands can let users test different styles.
LinkedIn: B2B commerce evolution
LinkedIn’s professional network offers unique advantages for B2B ecommerce. The platform’s business-focused audience actively seeks industry insights and solutions. So, focus your LinkedIn content on solving business challenges by:
• Sharing detailed case studies about customer successes
• Posting product demonstration videos
• Publishing industry research and trend analysis
• Showcasing customer testimonials through carousels
X: real-time commerce engagement
X (formerly Twitter) excels at immediate, event-driven engagement. The platform’s real-time nature makes it ideal for flash sales and limited-time offers. Users here expect quick responses and authentic interactions.
Time your X promotions around relevant conversations by:
• Launching flash sales during peak engagement times
• Responding to trending topics with relevant product tie-ins
• Using polls to gather instant feedback
• Creating urgency with countdown tweets
Reddit: community-first approach
Reddit’s structure demands a different advertising approach. Each subreddit functions as its own community with unique rules and culture. Success here requires genuine participation before promotion.
Build credibility through authentic Reddit engagement by:
• Answering questions in relevant subreddits
• Sharing expert knowledge without direct selling
• Hosting AMA (Ask Me Anything) sessions
• Addressing customer service issues publicly
Focus on subreddits where your expertise adds value to existing discussions, rather than creating purely promotional content.
Key takeaways
Success in ecommerce advertising demands a strategic balance across multiple platforms. To maximize your advertising impact:
• Choose platforms strategically: Select channels based on where your high-value customers spend time, not where advertising costs least.
• Use data intelligently: Connect your zero- and first-party customer data to ad platforms for more precise targeting and better returns.
• Adapt to each platform: Create native content that respects each platform’s unique characteristics while maintaining your brand voice.
The future of ecommerce advertising lies in seamlessly connecting these platforms while staying agile enough to embrace new channels as they emerge.
By combining Klaviyo’s data and owned channel capabilities with third-party advertising platforms, you get the best of both worlds. Use platforms like Amazon and social media ads for broad reach and customer acquisition, then leverage Klaviyo’s integrations with Meta, TikTok, Google Ads, Pinterest, and more to bring those leads back to your owned channels.
This hybrid approach lets you expand your reach while building deeper customer relationships through zero- and first-party data—turning marketplace browsers into loyal, direct customers.
Facebook Advertising use cases
Explore our running list of ways brands like yours use Klaviyo’s integration with Meta to acquire more customers.
Unlock Instagram as a channel for growth
Instagram advertising is one thing, but there are so many more ways to use this platform to unlock growth.
12 Pinterest marketing tips
Don’t underestimate this visual social media platform. Learn how to use this advertising powerhouse.