AI that creates, resolves, and optimizes— autonomously
From uncovering new opportunities to launching on-brand campaigns and providing support 24/7, K:AI agents keep your business moving while built-in AI tools optimize every interaction for the biggest impact.
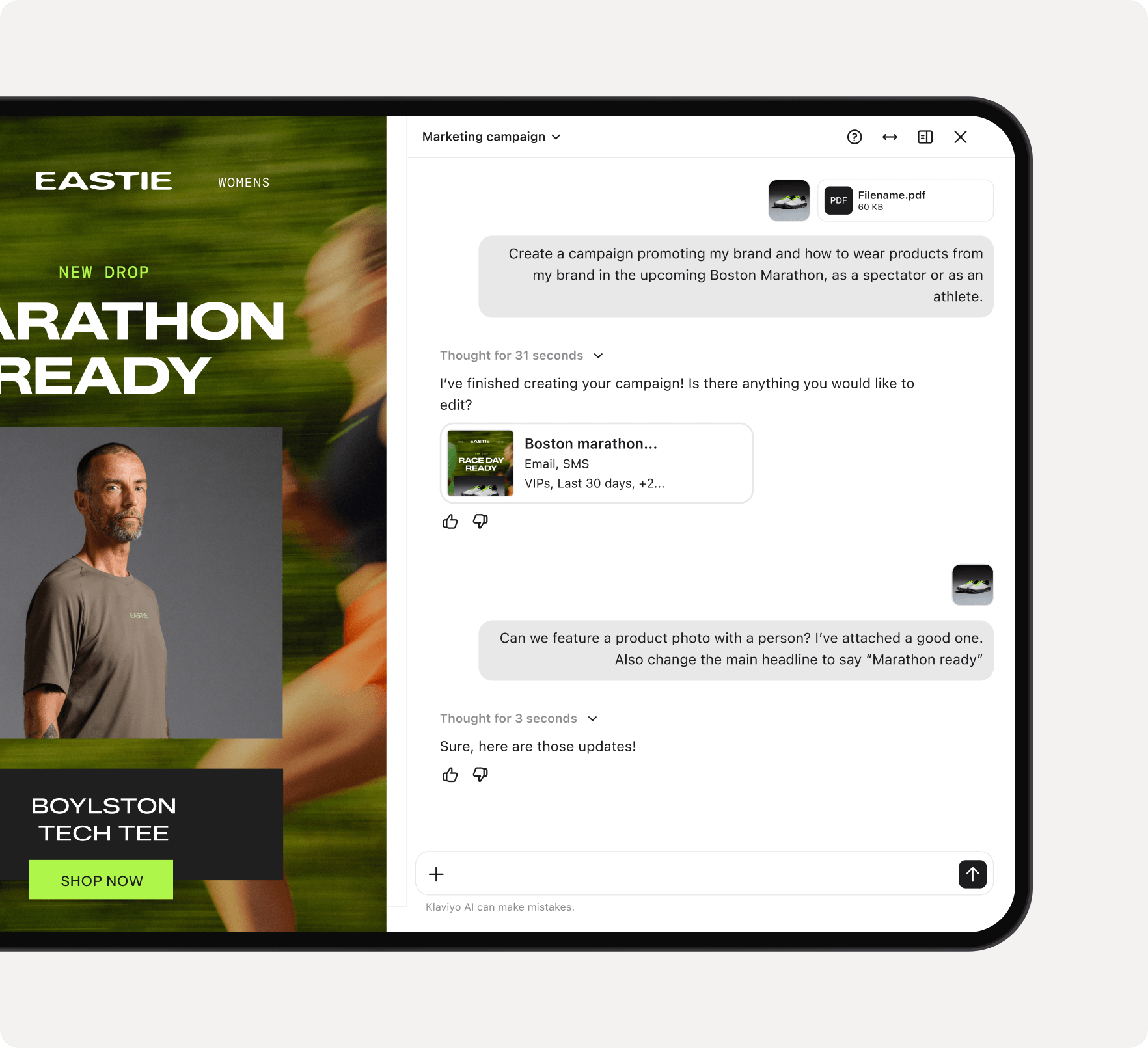
Goodbye monotonous. Hello autonomous.
Composer
Tell Composer what you're trying to achieve, and it'll uncover opportunities, build the audience, draft the content, and plan the send.
Customer Agent
Support and sell. 24/7 support answers common customer questions while identifying sales opportunities.
Personalization
Automatically hone your strategy across audiences, channels, content, and timing with 40+ predictive and generative features.
Integrations
Access Klaviyo data within Claude, ChatGPT, or any AI tool you like with Klaviyo's MCP server.
Discover your next best revenue opportunity and act on it
Spot new revenue opportunities, turn an idea into a launch-ready campaign in minutes, and move forward with confidence—all through a simple conversation.
See what's holding growth back
Composer analyzes your performance across campaigns, segments, and flows to find opportunities with the greatest revenue potential.
Go from prompt to campaign in minutes
What used to take hours can now take minutes. Tell Composer what you're trying to accomplish and it'll build the campaign for you,
Make decisions with confidence
Every recommendation comes with the context behind it, drawing on performance data, account history, and Klaviyo expertise so you can decide what's worth doing next.
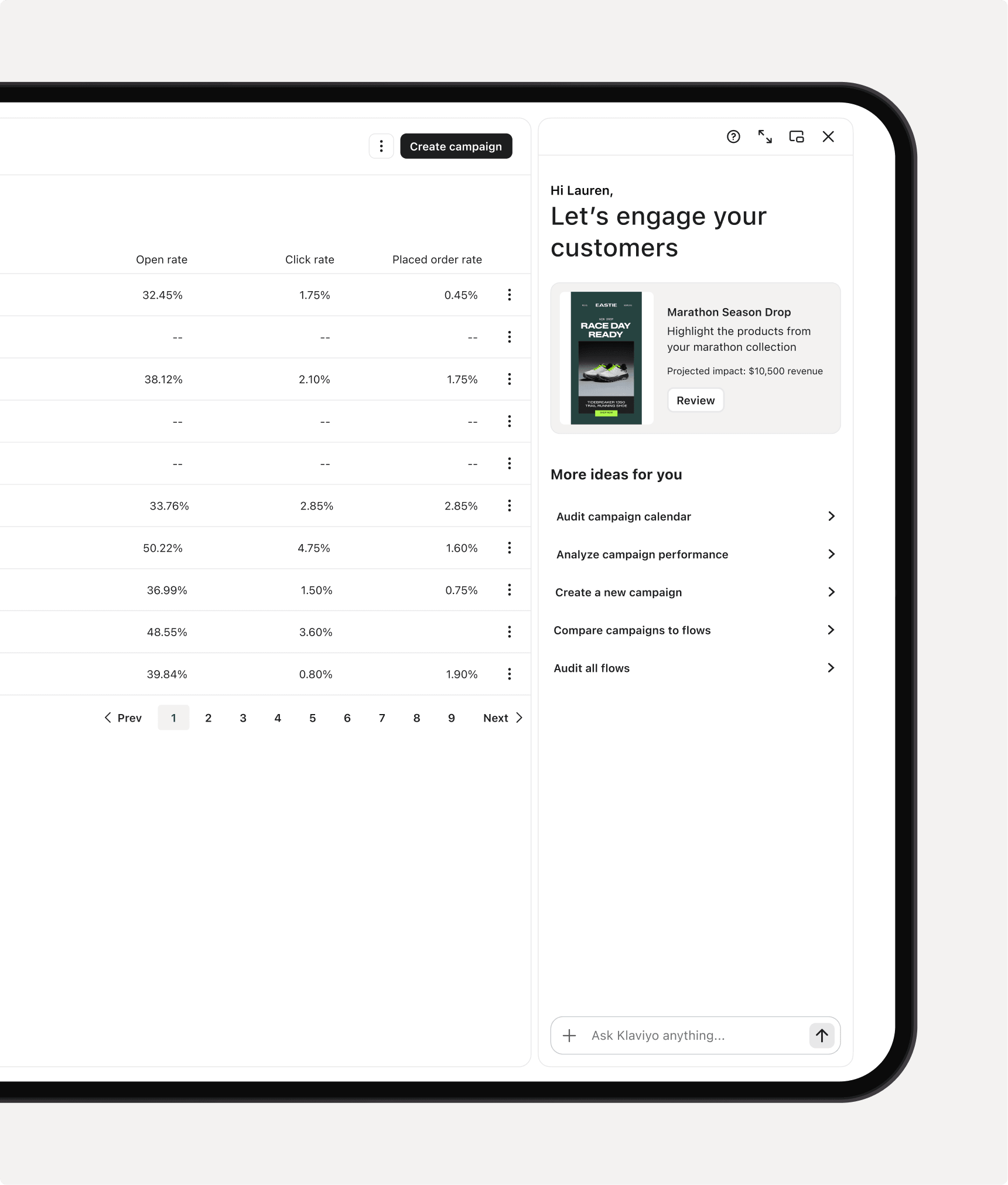
The AI customer service agent that already knows your customers
Built for B2C. Resolve questions, recommend products, and drive revenue, powered by everything Klaviyo knows about your customers.
Ready from day one
Pre-trained on your data, policies, and brand voice. For anything unique to your business, just describe it. Klaviyo builds it for you.
Works across your tech stack
Connect your existing tools through integrations or APIs so Customer Agent can take action on behalf of your customers, automatically.
Keep your brand intact
Test every response before it reaches a customer, so it stays on-brand, on-policy, and consistent across channels and languages.
Make every conversation more valuable
Conversations don't just get resolved — they enrich your customer profiles, making every future campaign, follow-up, and flow more personalized.
Built-in trust and reliability
No black boxes. Full audit trails, built-in simulations, and guardrails keep your agent on-brand and on-policy, so your team can focus on what matters.
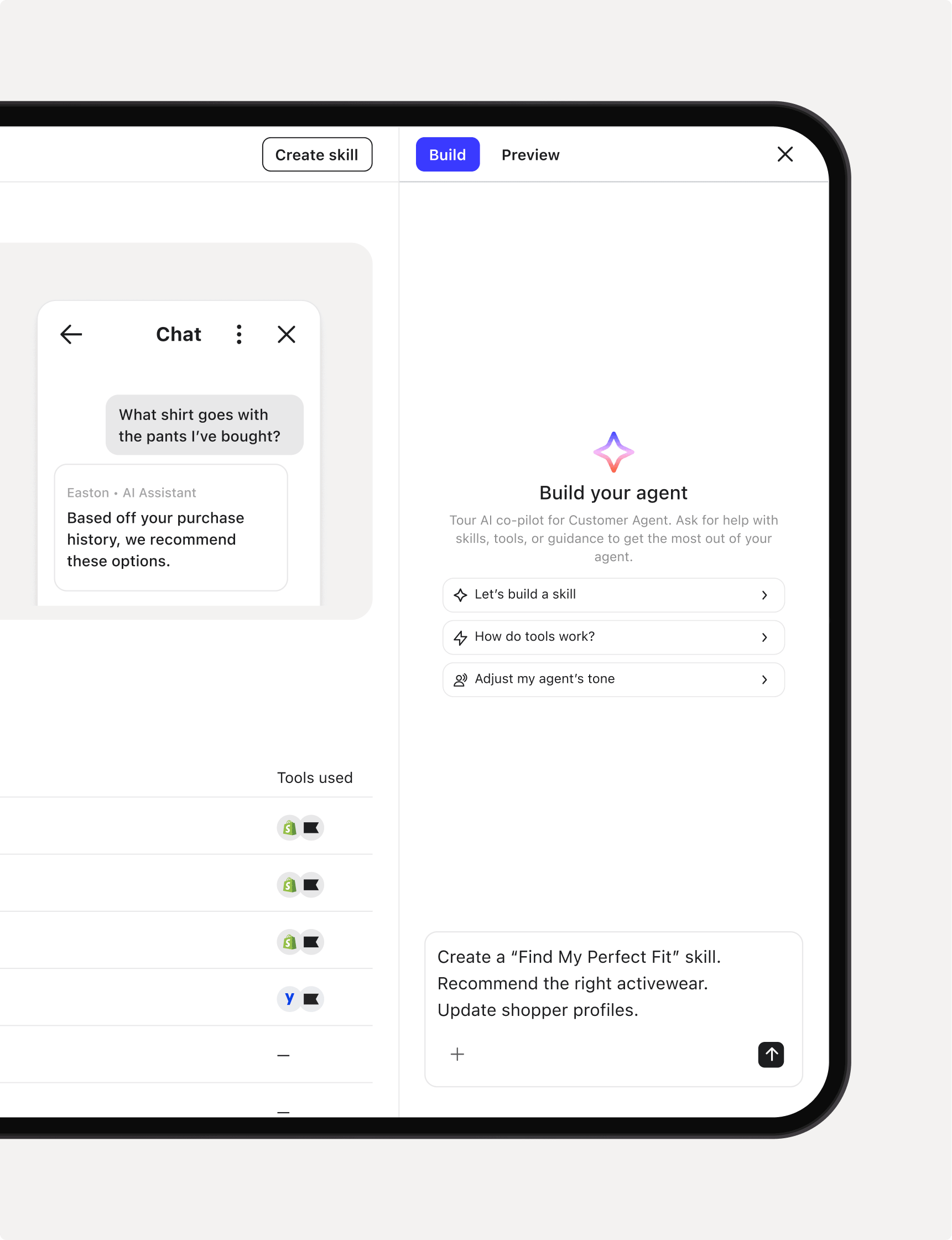
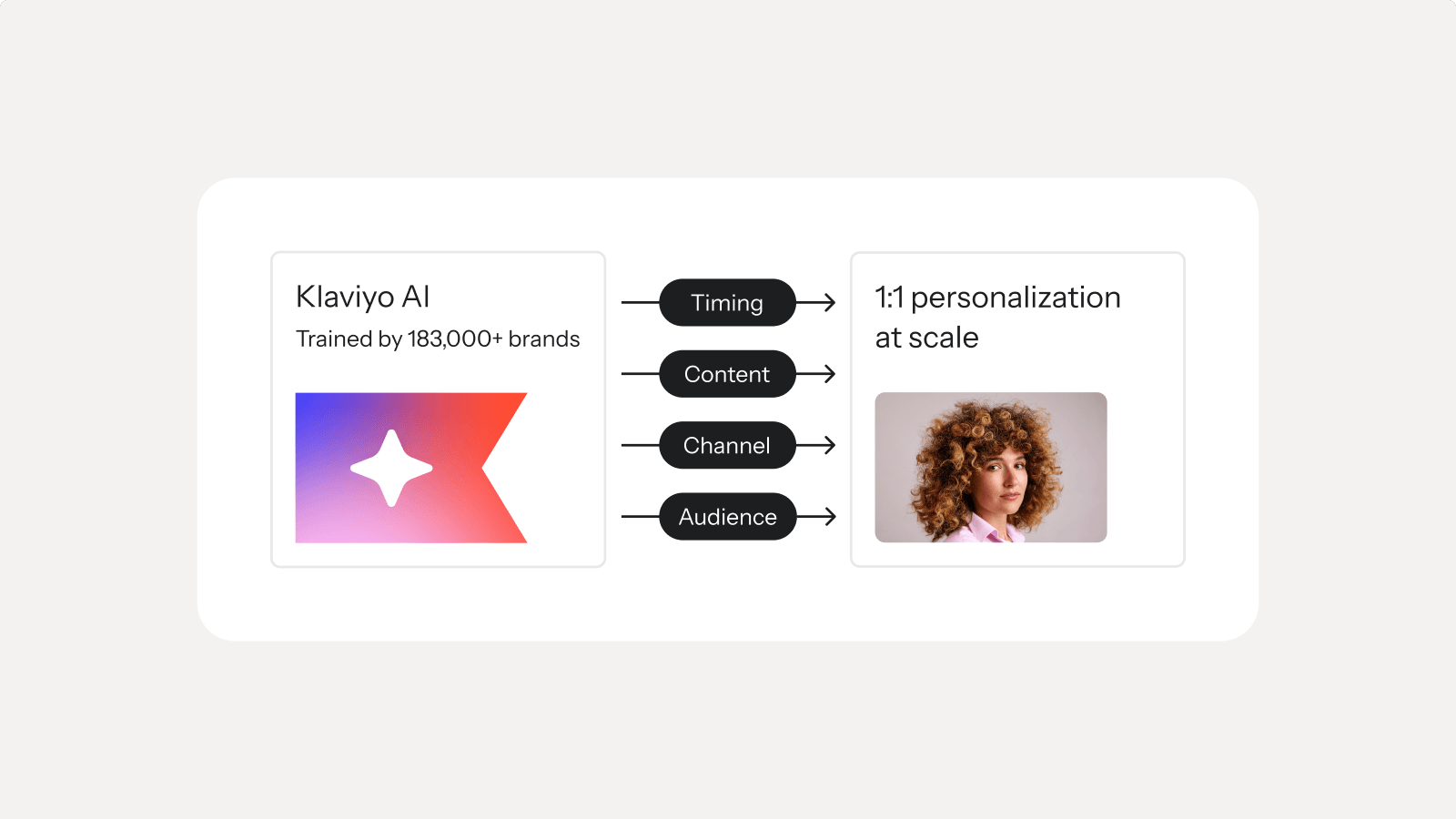
Personalization that keeps customers coming back
K:AI handles who to reach, what to say, and when to send it—personalizing every message with the right products. All driven by your data.
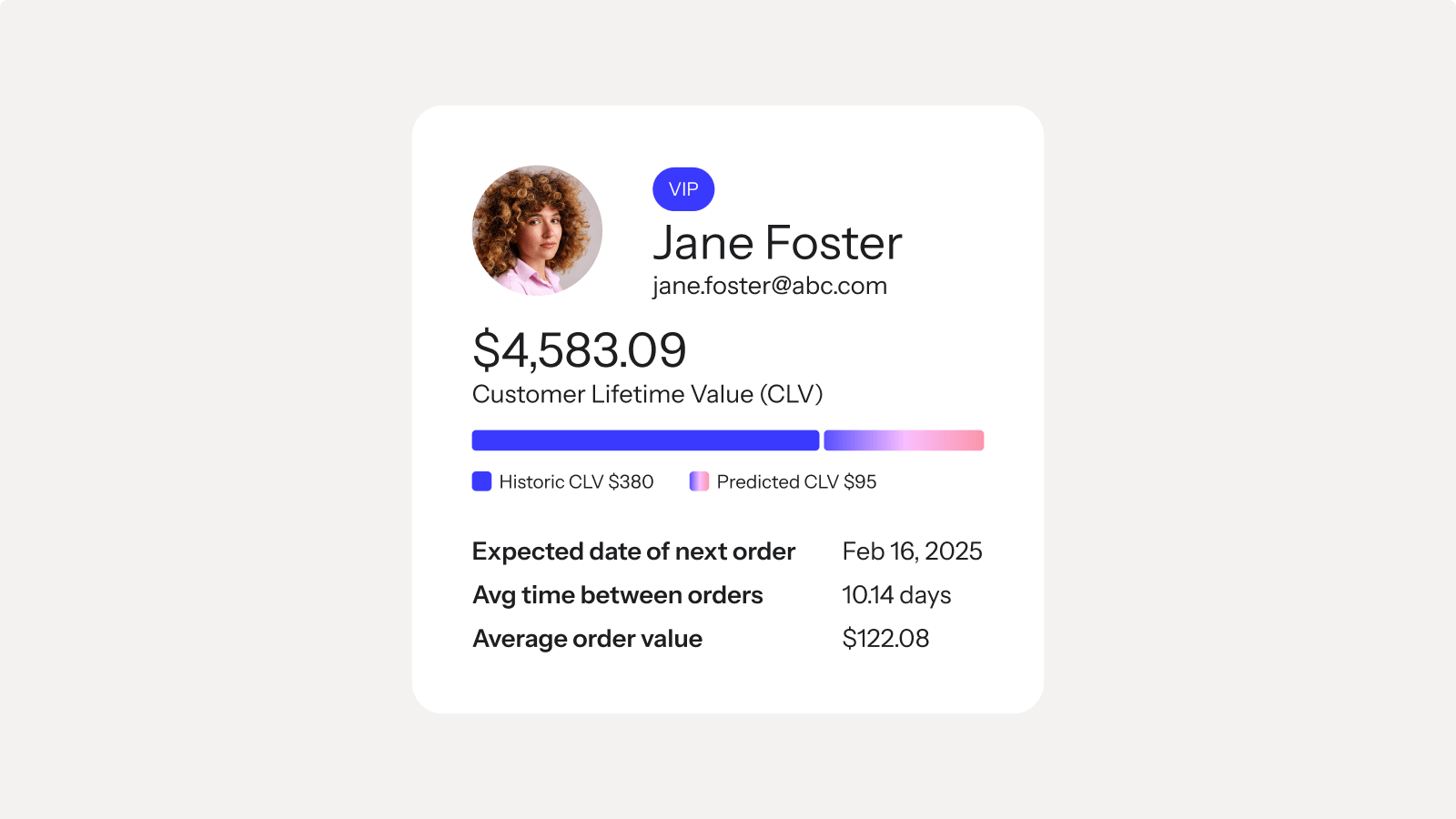
Understand which customers to focus on and when
K:AI scores every customer on lifetime value, churn risk, and purchase patterns—so you always know who to target and who’s ready to buy.
Features: Predicted CLV · RFM analysis · churn risk
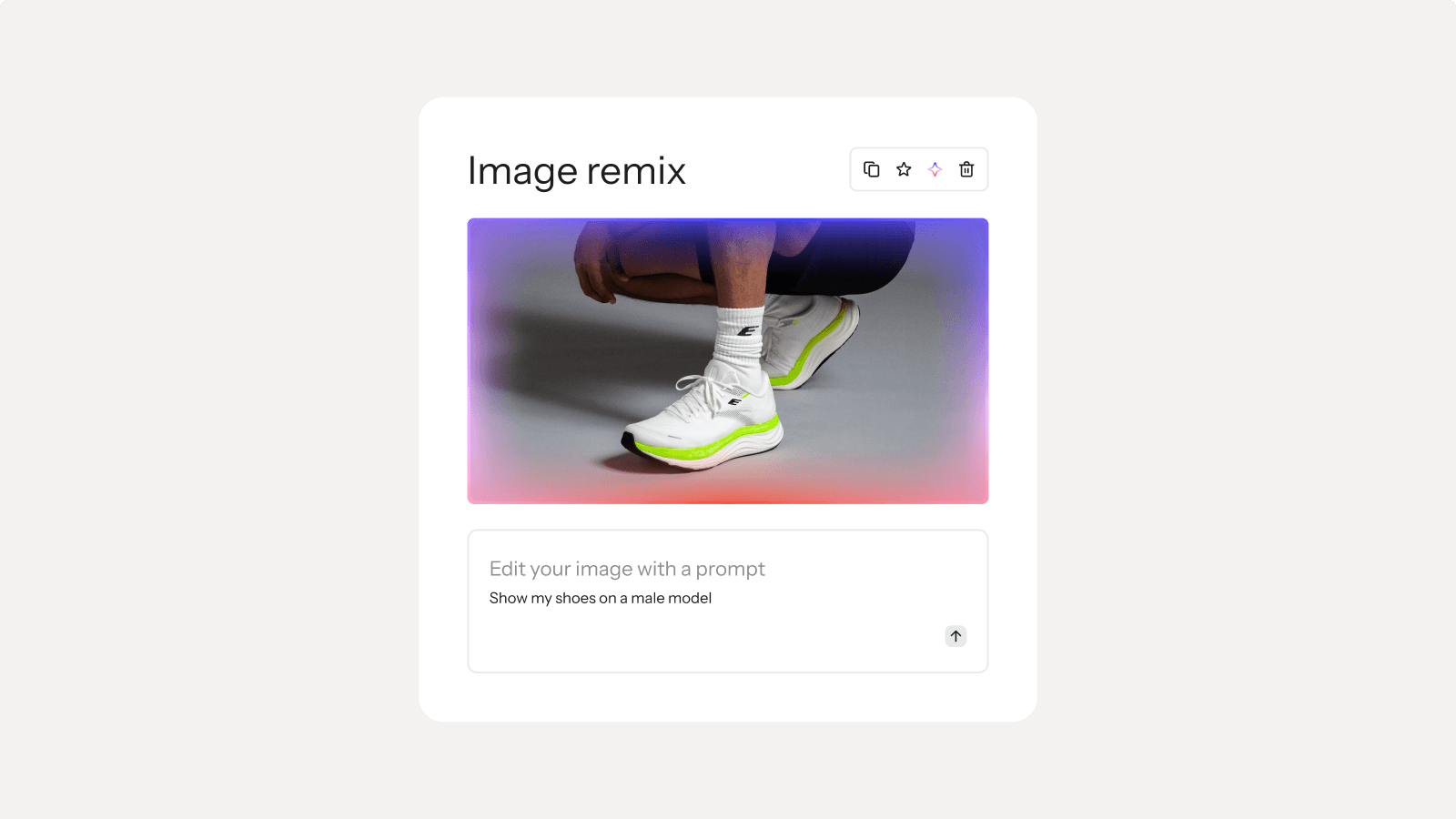
Generate high-performing content in minutes
K:AI enhances what you create—refining content, personalizing messages, and optimizing delivery across every channel, automatically.
Features: Composer · brand voice AI · segment AI · flows AI · Image Remix · smart translations
Reach customers where and when they convert with right offers
K:AI routes each customer to their preferred channel, delivers at the moment they’re most likely to engage, and personalizes what they see—across email, SMS, mobile, and your website.
Features: Personalized Send Time · channel affinity · product recommendations · audience optimization

Experiment, detect, and continuously improve
K:AI keeps your campaigns improving and protected—testing what works, rolling out winners, and watching deliverability behind the scenes so nothing slips through.
Features: Forms optimization AI · personalized campaigns · flow anomaly detection · campaign deliverability monitoring · volume warnings · guided warming
AI that works where you do

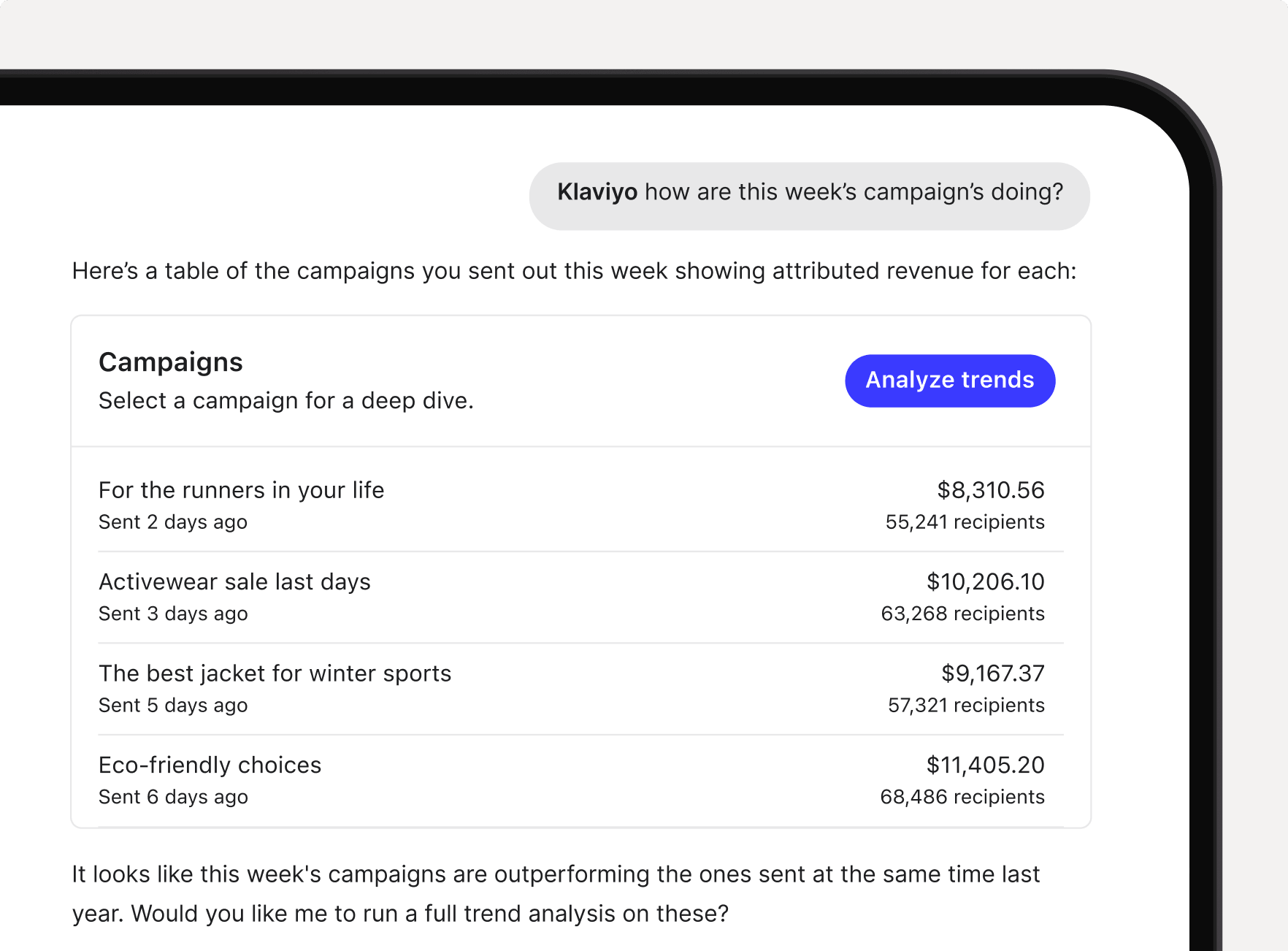
Klaviyo Claude app
When you want to go deeper, Claude feels less like a tool and more like someone who can just take this off your plate. It pulls your Klaviyo data, figures out what needs to be done, and turns it into finished work you can actually use.
Klaviyo ChatGPT app
Ask a question, get an answer, and take action—without breaking your flow. It’s everything you need, right where you’re already working.
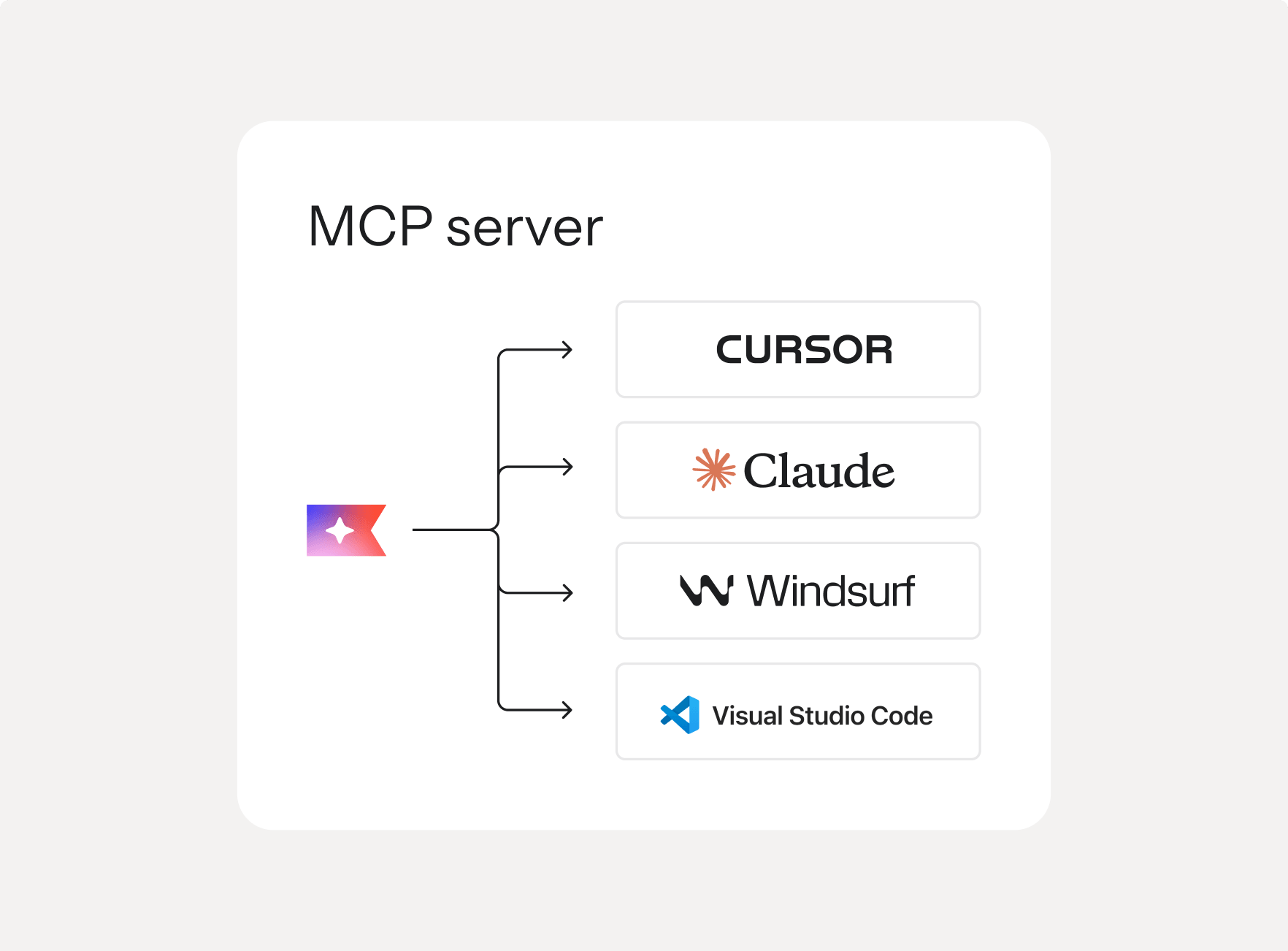
Klaviyo MCP server
Connect any AI agent or tool directly to your Klaviyo data. Build custom workflows, power your own tools, and bring AI into Klaviyo on your terms.
“Klaviyo, supercharged by its powerful AI features, enables us to easily and effectively build complex automated flows that deliver the right message to the right customers, in the right region, at the right time.”
Jarrod Hinvest, Head of ecommerce, Culture Kings
Why K:AI?
It works where you work
K:AI is embedded in every Klaviyo workflow and acts on your behalf across marketing, service, and analytics.
Data you own and trust
K:AI is trained on your brand, website, catalog, and profiles—because AI is only as good as your data.
Continuous innovation
We’ve been building AI features since 2017, with over 40 features available today—and counting.
Open by design
Our remote MCP server allows you to connect Klaviyo B2C CRM with your preferred AI tools.
AI your way
With K:AI, you have the power to use AI your way—from predictive AI for insights and speed to assistive AI for co-creation—and now, K:AI agents that act autonomously.

Klaviyo AI tools and resources
AI for email marketing
Create and optimize high-performing emails with AI-driven insights
What is AI in marketing?
Discover the benefits of using AI in marketing, how marketing teams are using AI, and how to track its effectiveness.
Klaviyo MCP server
Learn how you can connect all your Klaviyo data with the AI tools you use everyday.
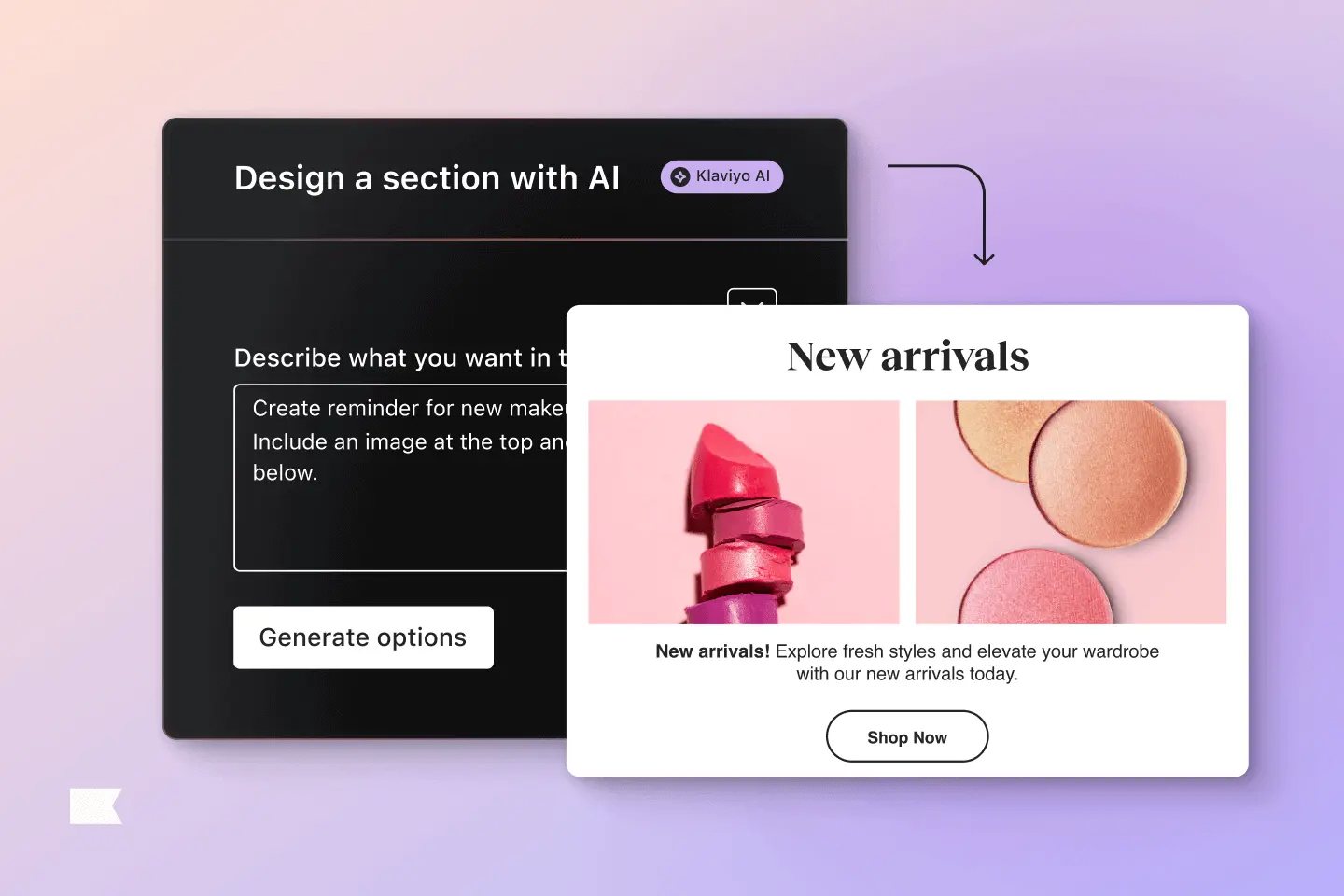
Top 6 use cases for Klaviyo Image Remix
Be inspired by the prompts marketers like you are using to easily and instantly update their images with Remix.
Explore the rest of the B2C CRM
Klaviyo AI FAQ
K:AI is AI powering built-in agents that use your real-time customer profile to plan and launch marketing, personalize every send, and resolve customer request—on one platform, with humans in the loop. Learn more about Composer and Customer Agent.