This article explains how to automate large-scale Klaviyo profile updates using AWS S3-triggered ingestion via Klaviyo’s SFTP import tool. It covers SFTP setup in Klaviyo, AWS IAM/S3/Lambda configuration, and deploying code to move CSV data from S3 into Klaviyo.
Use case overviewDescribes when S3-triggered SFTP ingestion is useful, such as bulk daily profile updates and syncing rewards or offline data into Klaviyo.
SFTP configuration stepsOutlines how to generate SSH keys, register them in Klaviyo’s SFTP tool, and capture server, username, and private key details for later use.
AWS setup requirementsDetails creating an IAM execution role, configuring access keys, setting up an S3 bucket, and wiring an AWS Lambda function to the S3 trigger.
Lambda and environmentExplains configuring Lambda with the correct role, adding code from GitHub, and setting environment variables for S3 and SFTP access.
End-to-end ingestion flowWalks through code that uploads and downloads CSV files in S3, prepares them for ingestion, connects to Klaviyo’s SFTP server, and updates profiles efficiently.
Solution Recipes are tutorials to achieve specific objectives in Klaviyo. They can also help you master Klaviyo, learn new third-party technologies, and come up with creative ideas. They are written mainly for developers and technically-advanced users.
What you’ll learn:
1
In this Solution Recipe, we will outline how to connect AWS S3 to Klaviyo’s SFTP to trigger profile ingestion when a new file is added to an S3 bucket. While this recipe covers AWS S3, you can apply this solution to connect any code hosting platform to Klaviyo’s SFTP.
Why it matters:
2
Increasingly, customers need a reliable solution that allows them to effortlessly import a large amount of data. A lot of Klaviyo customers rely on SFTP ingestion to quickly and accurately ingest data. By leveraging AWS, specifically S3 and Lambda, users can trigger ingestion when a new file is added to an S3 bucket, creating a more automatic ingestion schedule that scales for large data sets.
Level of sophistication:
3
Moderate
Introduction
It is time consuming to update and import a large number of profiles (i.e., 500K+). We will outline an AWS-based solution that utilizes an S3 bucket and Klaviyo’s SFTP import tool to reduce the time required to make updates and automate key parts of the process.
When using an S3-triggered SFTP ingestion, you can streamline and automate the process of importing data, which ultimately improves the overall experience of accurately and effectively maintaining customer data and leveraging Klaviyo’s powerful marketing tools. Some use cases that may require this type of solution include a bulk daily sync to update profile properties with rewards data or updating performance results from a third-party integration.
Other key profile attributes you may want to update in bulk and leverage for greater personalization in Klaviyo include:
Birthdate
Favorite brands
Loyalty
Properties from off-line sources
In this solution recipe, we’ll walk through:
Setting up your SFTP credentials
Configuring your AWS account with the required IAM, S3 and Lambda settings
Deploying code to programmatically ingest a CSV file into Klaviyo via our SFTP server.
The goal is to streamline and accelerate the process of ingesting profile data into Klaviyo using AWS services and Klaviyo’s SFTP import tool.
We will provide in-depth, step-by-step instructions throughout this Solution Recipe. The more broad overview of steps are:
Create an SSH key pair and prepare for SFTP ingestion.
Set up an AWS account with access to IAM, S3, and Lambdaa. Create an IAM execution role for Lambdab. Create and record security credentialsc. Create an S3 bucketd. Configure a Lambda function with the IAM execution role and set the S3 bucket as the triggere. Configure AWS environment variables.
Deploy the Lambda function and monitor progress to ensure profiles are updated and displayed in Klaviyo’s UI as anticipated.
Instructions for SFTP configuration
Step 1: Create SSH key pair and prepare for SFTP ingestion
SFTP is only available to Klaviyo users with an Owner, Admin, or Manager role. To start, you’ll need to generate a public/private key pair on your local machine using ssh-keygen or a tool of your choice. Refer to this documentation for the supported SSH key formats.
Once you have generated your keys:
In Klaviyo, click your account name in the lower left corner and select “Integrations“
On the Integrations page, click “Manage Sources” in the upper right, then select “Import via SFTP“
Click “Add a new SSH Key“
Paste your public key into the “SSH Key” box
Click “Add key”
Record the following details so you can add them into your AWS Environment Variables in the next step:
Server: sftp.klaviyo.com
Username: Your_SFTP_Username (abc123_def456)
SSH Private Key: the private key associated with the public key generated in previous steps
You can read up on our SFTP tool by visiting our developer portal.
Instructions for AWS implementation
Step 2A. Create an IAM Execution role for Lambda
Create an IAM role with AWS service as the trusted entity and Lambda as the use-case.
The Lambda will require the following policy names: AmazonS3FullAccessAmazonAPIGatewayInvokeFullAccessAWSLambdaBasicExecutionRole
AmazonS3FullAccess
AmazonAPIGatewayInvokeFullAccess
AWSLambdaBasicExecutionRole
Step 2B. Set up your access key ID and secret access key
You will need to set up your access key ID and secret access key in order to give access to the files to be uploaded from the local machine.
Open the “Security credentials” tab, and then choose “Create access key”
To see the new access key, choose “Show”
To download the key pair, choose “Download .csv file“. Store the file in a secure location. You will add these values into your AWS Environment Variables.
Note: You can retrieve the secret access key only when you create the key pair. Like a password, you can’t retrieve it later. If you lose it, you must create a new key pair.
The Lambda is the component of this set-up used to start up the SFTP connection and ingest the CSV file.
Create a new Lambda function with the execution role configured in step 2A.
Update the Trigger settings with the S3 bucket created in step 2C.
Add corresponding files into Lambda from GitHub.
We’ll do a code deep dive in step 3.
Step 2E. Configure AWS environment variables.
Navigate to the “Configuration” tab and add the following resources into your Environment Variables with their corresponding values.
text
# AWS access and secret keysACCESS_KEY_IDSECRET_ACCESS_KEYS3_BUCKET_NAME# folder path to where you are saving your S3 file locallyFOLDER_PATHExample: /Users/tyler.berman/Documents/SFTP/S3_FILE_NAMEExample: unmapped_profiles.csvLOCAL_FILE_NAMEExample: unmapped_profiles_local.csvMAPPED_FILE_NAMEExample: mapped_profiles.csv# add your 6 digit List ID found in the URL of the subscriber listLIST_IDExample: ABC123PROFILES_PATH = /profiles/profiles.csv# folder path to where your SSH private key is storedPRIVATE_KEY_PATHExample: /Users/tyler.berman/.ssh/id_rsaHOST = sftp.klaviyo.com# add your assigned username found in the UI of Klaviyo's SFTP import toolUSERNAMEExample: abc123_def456
Step 3: Deploy your code
Let’s review the code deployed in your AWS instance.
Programmatically add CSV file to S3:
text
import boto3import ossession = boto3.Session( aws_access_key_id = os.environ['ACCESS_KEY_ID'], aws_secret_access_key = os.environ['SECRET_ACCESS_KEY'])s3 = session.resource('s3')#Define the bucket name and file namebucket_name = os.environ['S3_BUCKET_NAME']#The name you want to give to the file in S3s3_file_name = os.environ['S3_FILE_NAME'] local_file = os.environ['LOCAL_FILE_NAME']s3.meta.client.upload_file(Filename=local_file, Bucket=bucket_name,Key=s3_file_name)
import pandas as pdimport os#anticipate column mapping based on commonly used headersdef suggest_column_mapping(loaded_file): column_mapping = { 'Email': ['EmailAddress', 'person.email', 'Email', 'email', 'emailaddress', 'email address', 'Email Address', 'Emails'], 'PhoneNumber': ['Phone#', 'person.number', 'phone', 'numbers', 'phone number', 'Phone Number'] } suggested_mapping = {} for required_header, old_columns in column_mapping.items(): for column in old_columns: if column in loaded_file.columns: suggested_mapping[column] = required_header return suggested_mapping#map column headers of S3 file and add List ID columndef map_column_headers(loaded_file): mapped_file = loaded_file.rename(columns=suggest_column_mapping(loaded_file), inplace=False) mapped_file['List ID'] = os.environ['LIST_ID'] final_file = os.environ['FOLDER_PATH'] + os.environ['MAPPED_FILE_NAME'] mapped_file.to_csv(final_file, index=False) return final_file
Establish SFTP server connection:
text
import pysftpimport os#ingest S3 file via SFTPdef connect_to_sftp_and_import_final_csv(final_file): with pysftp.Connection(host=os.environ['HOST'], username=os.environ['USERNAME'], private_key=os.environ['PRIVATE_KEY_PATH']) as sftp: print(f"Connected to {os.environ['HOST']}!") try: sftp.put(final_file, os.environ['PROFILES_PATH']) print(f"Imported {final_file}. Check your inbox for SFTP job details. View progress at https://www.klaviyo.com/sftp/set-up") except Exception as err: raise Exception(err) # close connection pysftp.Connection.close(self=sftp) print(f"Connection to {os.environ['HOST']} has been closed.")
Put it all together in a lambda_handler function to ingest S3 file via SFTP:
Using Klaviyo’s SFTP tool makes data ingestion faster and more efficient. When coupled with the power of AWS’s S3 and Lambda services, you can boost its automation and scalability. With this configuration, your team will be able to manage data and execute ingestion with speed and accuracy, reducing the time and burden of updating profiles manually. Moreover, you can significantly improve data accuracy and mitigate the risk of errors during the ingestion process, ensuring the reliability and integrity of the data you’re using.
Overall, this solution optimizes the efficiency and effectiveness of leveraging relevant data in Klaviyo while streamlining operations and enhancing overall performance.
How to update profile properties in Klaviyo using the Klaviyo Profiles API endpoint
# Solution Recipe 24: AWS S3-triggered ingestion via Klaviyo’s SFTP
_Solution Recipes are tutorials to achieve specific objectives in Klaviyo. They can also help you master Klaviyo, learn new third-party technologies, and come up with creative ideas. They are written mainly for developers and technically-advanced users._
```json
{
"_key": "1775e534-2ae4-4daf-a47e-baa4f4c60762",
"_type": "steps",
"steps": [
{
"_key": "863bf77a-a573-44de-bbfe-d8fbfab97c70",
"_type": "step",
"body": [
{
"_key": "EqVQHfTxd77S2dS0rrRgUl",
"_type": "block",
"children": [
{
"_key": "EqVQHfTxd77S2dS0rrRgYB",
"_type": "span",
"marks": [],
"text": "In this Solution Recipe, we will outline how to connect AWS S3 to Klaviyo’s SFTP to trigger profile ingestion when a new file is added to an S3 bucket. While this recipe covers AWS S3, you can apply this solution to connect any code hosting platform to Klaviyo’s SFTP."
}
],
"markDefs": [],
"style": "normal"
}
],
"title": "What you’ll learn:"
},
{
"_key": "3534086e-14f6-402b-b837-a4bb855585d5",
"_type": "step",
"body": [
{
"_key": "EqVQHfTxd77S2dS0rrRgbb",
"_type": "block",
"children": [
{
"_key": "EqVQHfTxd77S2dS0rrRgf1",
"_type": "span",
"marks": [],
"text": "Increasingly, customers need a reliable solution that allows them to effortlessly import a large amount of data. A lot of Klaviyo customers rely on SFTP ingestion to quickly and accurately ingest data. By leveraging AWS, specifically S3 and Lambda, users can trigger ingestion when a new file is added to an S3 bucket, creating a more automatic ingestion schedule that scales for large data sets. "
}
],
"markDefs": [],
"style": "normal"
}
],
"title": "Why it matters:"
},
{
"_key": "7dfb9532-4d8b-4f29-84b3-20a9d27f53e7",
"_type": "step",
"body": [
{
"_key": "EqVQHfTxd77S2dS0rrRgiR",
"_type": "block",
"children": [
{
"_key": "EqVQHfTxd77S2dS0rrRglr",
"_type": "span",
"marks": [],
"text": "Moderate"
}
],
"markDefs": [],
"style": "normal"
}
],
"title": "Level of sophistication:"
}
]
}
```
## **Introduction**
It is time consuming to update and import a large number of profiles (i.e., 500K+). We will outline an AWS-based solution that utilizes an S3 bucket and Klaviyo’s SFTP import tool to reduce the time required to make updates and automate key parts of the process.
When using an S3-triggered SFTP ingestion, you can streamline and automate the process of importing data, which ultimately improves the overall experience of accurately and effectively maintaining customer data and leveraging Klaviyo’s powerful marketing tools. Some use cases that may require this type of solution include a bulk daily sync to update profile properties with rewards data or updating performance results from a third-party integration.
Other key profile attributes you may want to update in bulk and leverage for greater personalization in Klaviyo include:
- Birthdate
- Favorite brands
- Loyalty
- Properties from off-line sources
In this solution recipe, we’ll walk through:
1. Setting up your SFTP credentials
2. Configuring your AWS account with the required IAM, S3 and Lambda settings
3. Deploying code to programmatically ingest a CSV file into Klaviyo via our SFTP server.
The goal is to streamline and accelerate the process of ingesting profile data into Klaviyo using AWS services and Klaviyo’s SFTP import tool.
## **Ingredients**
- GitHub Link [Repo](https://github.com/klaviyo-labs/s3-triggered-sftp-ingestion)
- Klaviyo [SFTP](https://developers.klaviyo.com/en/docs/use_klaviyos_sftp_import_tool) Import tool
- [AWS Lambda with S3](https://docs.aws.amazon.com/lambda/latest/dg/with-s3.html)
- Python Libraries: [pandas](https://pandas.pydata.org/), [pysftp](https://pypi.org/project/pysftp/), [boto3](https://pypi.org/project/boto3/)
## **Instructions**
We will provide in-depth, step-by-step instructions throughout this Solution Recipe. The more broad overview of steps are:
1. Create an SSH key pair and prepare for SFTP ingestion.
2. Set up an AWS account with access to [IAM](https://console.aws.amazon.com/iam/), [S3](https://console.aws.amazon.com/s3/), and [Lambda](https://console.aws.amazon.com/lambda/)a. Create an IAM execution role for Lambdab. Create and record security credentialsc. Create an S3 bucketd. Configure a Lambda function with the IAM execution role and set the S3 bucket as the triggere. Configure AWS environment variables.
3. Deploy the Lambda function and monitor progress to ensure profiles are updated and displayed in Klaviyo’s UI as anticipated.
### **Instructions for SFTP configuration**
#### **Step 1: Create SSH key pair and prepare for SFTP ingestion**
SFTP is only available to Klaviyo users with an Owner, Admin, or Manager role. To start, you’ll need to generate a public/private key pair on your local machine using [ssh-keygen](https://docs.github.com/en/authentication/connecting-to-github-with-ssh/generating-a-new-ssh-key-and-adding-it-to-the-ssh-agent) or a tool of your choice. Refer to this [documentation](https://docs.aws.amazon.com/transfer/latest/userguide/key-management.html) for the supported SSH key formats.
Once you have generated your keys:
1. In Klaviyo, click your account name in the lower left corner and select “**Integrations**“
2. On the Integrations page, click “Manage Sources” in the upper right, then select “**Import via SFTP**“
3. Click “**Add a new SSH Key**“
4. Paste your public key into the “SSH Key” box
5. Click “Add key”
Record the following details so you can add them into your AWS Environment Variables in the next step:
- **Server**: sftp.klaviyo.com
- **Username**: Your_SFTP_Username (abc123_def456)
- **SSH Private Key**: the private key associated with the public key generated in previous steps
You can read up on our SFTP tool by visiting our [developer portal](https://developers.klaviyo.com/en/docs/use_klaviyos_sftp_import_tool).
### **Instructions for AWS implementation**
#### **Step 2A. Create an IAM Execution role for Lambda**
1. Create an [IAM role](https://console.aws.amazon.com/iamv2/home?#/roles) with AWS service as the trusted entity and Lambda as the use-case.
2. The Lambda will require the following policy names:
AmazonS3FullAccessAmazonAPIGatewayInvokeFullAccessAWSLambdaBasicExecutionRole
- AmazonS3FullAccess
- AmazonAPIGatewayInvokeFullAccess
- AWSLambdaBasicExecutionRole
#### **Step 2B. Set up your access key ID and secret access key**
You will need to set up your access key ID and secret access key in order to give access to the files to be uploaded from the local machine.
1. Navigate to “Users” in the [IAM console](https://console.aws.amazon.com/iam/)
2. Choose your IAM username
3. Open the “Security credentials” tab, and then choose “Create access key”
4. To see the new access key, choose “Show”
5. To download the key pair, choose “**Download .csv file**“. Store the file in a secure location. You will add these values into your AWS Environment Variables.
**Note**: You can retrieve the secret access key only when you **_create_** the key pair. Like a password, you can’t retrieve it later. If you lose it, you must create a new key pair.
#### **Step 2C. Create S3 bucket**
Navigate here to [create the S3 bucket](https://console.aws.amazon.com/s3/).
#### **Step 2D. Configure a Lambda function**
The Lambda is the component of this set-up used to start up the SFTP connection and ingest the CSV file.
1. Create a new Lambda function with the execution role configured in step 2A.
2. Update the Trigger settings with the S3 bucket created in step 2C.
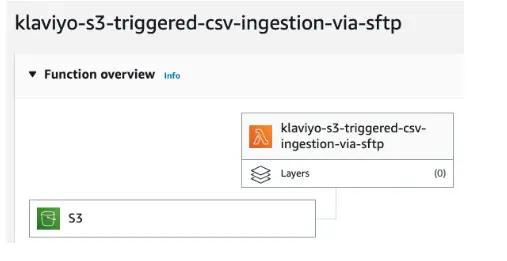
1. Add corresponding files into Lambda from GitHub.
We’ll do a code deep dive in step 3.
#### **Step 2E. Configure AWS environment variables.**
1. Navigate to the “Configuration” tab and add the following resources into your Environment Variables with their corresponding values.
```json
{
"_key": "569d2ad3-718c-4dc4-bb67-3095d4041d1c",
"_type": "codeSnippet",
"code": "# AWS access and secret keys\nACCESS_KEY_ID\nSECRET_ACCESS_KEY\n\nS3_BUCKET_NAME\n\n# folder path to where you are saving your S3 file locally\nFOLDER_PATH\nExample: /Users/tyler.berman/Documents/SFTP/\n\nS3_FILE_NAME\nExample: unmapped_profiles.csv\n\nLOCAL_FILE_NAME\nExample: unmapped_profiles_local.csv\n\nMAPPED_FILE_NAME\nExample: mapped_profiles.csv\n\n# add your 6 digit List ID found in the URL of the subscriber list\nLIST_ID\nExample: ABC123\n\nPROFILES_PATH = /profiles/profiles.csv\n\n# folder path to where your SSH private key is stored\nPRIVATE_KEY_PATH\nExample: /Users/tyler.berman/.ssh/id_rsa\n\nHOST = sftp.klaviyo.com\n\n# add your assigned username found in the UI of Klaviyo's SFTP import tool\nUSERNAME\nExample: abc123_def456",
"language": "text",
"theme": "github-light"
}
```
#### **Step 3: Deploy your code**
Let’s review the code deployed in your AWS instance.
1. Programmatically add CSV file to S3:
```json
{
"_key": "1d5fef98-fba6-4cc9-bb8b-af71b6754296",
"_type": "codeSnippet",
"code": "import boto3\nimport os\n\n\nsession = boto3.Session(\n aws_access_key_id = os.environ['ACCESS_KEY_ID'],\n aws_secret_access_key = os.environ['SECRET_ACCESS_KEY']\n)\n\ns3 = session.resource('s3')\n\n#Define the bucket name and file name\nbucket_name = os.environ['S3_BUCKET_NAME']\n#The name you want to give to the file in S3\ns3_file_name = os.environ['S3_FILE_NAME'] \nlocal_file = os.environ['LOCAL_FILE_NAME']\n\ns3.meta.client.upload_file(Filename=local_file, Bucket=bucket_name,Key=s3_file_name)",
"language": "text",
"theme": "github-light"
}
```
1. Download S3 file:
```json
{
"_key": "cc60721e-c850-424d-a4b6-2fed1e34d35d",
"_type": "codeSnippet",
"code": "import boto3\n\n\ndef download_file_from_s3(aws_access_key_id, aws_secret_access_key, bucket_name, s3_file_name, downloaded_file):\n session = boto3.Session(\n aws_access_key_id=aws_access_key_id,\n aws_secret_access_key=aws_secret_access_key\n )\n\n s3 = session.resource('s3')\n \n s3.meta.client.download_file(Bucket=bucket_name, Key=s3_file_name, Filename=downloaded_file)",
"language": "text",
"theme": "github-light"
}
```
1. Prepare CSV file for ingestion:
```json
{
"_key": "3eacba55-60d7-447c-a973-ccaab6f8e862",
"_type": "codeSnippet",
"code": "import pandas as pd\nimport os\n\n\n#anticipate column mapping based on commonly used headers\ndef suggest_column_mapping(loaded_file):\n column_mapping = {\n 'Email': ['EmailAddress', 'person.email', 'Email', 'email', 'emailaddress', 'email address', 'Email Address', 'Emails'],\n 'PhoneNumber': ['Phone#', 'person.number', 'phone', 'numbers', 'phone number', 'Phone Number']\n }\n\n suggested_mapping = {}\n for required_header, old_columns in column_mapping.items():\n for column in old_columns:\n if column in loaded_file.columns:\n suggested_mapping[column] = required_header\n\n return suggested_mapping\n\n\n#map column headers of S3 file and add List ID column\ndef map_column_headers(loaded_file):\n mapped_file = loaded_file.rename(columns=suggest_column_mapping(loaded_file), inplace=False)\n mapped_file['List ID'] = os.environ['LIST_ID']\n\n final_file = os.environ['FOLDER_PATH'] + os.environ['MAPPED_FILE_NAME']\n mapped_file.to_csv(final_file, index=False)\n\n return final_file",
"language": "text",
"theme": "github-light"
}
```
1. Establish SFTP server connection:
```json
{
"_key": "376b7423-e678-47a9-a1ea-9031eb3448e2",
"_type": "codeSnippet",
"code": "import pysftp\nimport os\n\n\n#ingest S3 file via SFTP\ndef connect_to_sftp_and_import_final_csv(final_file):\n with pysftp.Connection(host=os.environ['HOST'],\n username=os.environ['USERNAME'],\n private_key=os.environ['PRIVATE_KEY_PATH']) as sftp:\n print(f\"Connected to {os.environ['HOST']}!\")\n try:\n sftp.put(final_file, os.environ['PROFILES_PATH'])\n print(f\"Imported {final_file}. Check your inbox for SFTP job details. View progress at https://www.klaviyo.com/sftp/set-up\")\n\n except Exception as err:\n raise Exception(err)\n\n # close connection\n pysftp.Connection.close(self=sftp)\n print(f\"Connection to {os.environ['HOST']} has been closed.\")",
"language": "text",
"theme": "github-light"
}
```
1. Put it all together in a lambda_handler function to ingest S3 file via SFTP:
```json
{
"_key": "a088cbc3-e75f-417e-b5c2-b99455fde8cb",
"_type": "codeSnippet",
"code": "import configure_csv\nimport sftp_connection\nimport s3_download\nimport os\nimport pandas as pd\nimport json\n\n\ndef lambda_handler(event, context):\ns3_download.download_file_from_s3(os.environ['ACCESS_KEY_ID'],\nos.environ['SECRET_ACCESS_KEY'],os.environ['S3_BUCKET_NAME'],\nos.environ['S3_FILE_NAME'],os.environ['FOLDER_PATH'] + os.environ['LOCAL_FILE_NAME'])\nloaded_file = pd.read_csv(os.environ['FOLDER_PATH'] + os.environ['LOCAL_FILE_NAME'])\n final_file = configure_csv.map_column_headers(loaded_file)\n sftp_connection.connect_to_sftp_and_import_final_csv(final_file)\n\n return {\n 'statusCode': 200,\n 'body': json.dumps('successfully ran lambda'),\n }",
"language": "text",
"theme": "github-light"
}
```
## **Impact**
Using Klaviyo’s SFTP tool makes data ingestion faster and more efficient. When coupled with the power of AWS’s S3 and Lambda services, you can boost its automation and scalability. With this configuration, your team will be able to manage data and execute ingestion with speed and accuracy, reducing the time and burden of updating profiles manually. Moreover, you can significantly improve data accuracy and mitigate the risk of errors during the ingestion process, ensuring the reliability and integrity of the data you’re using.
Overall, this solution optimizes the efficiency and effectiveness of leveraging relevant data in Klaviyo while streamlining operations and enhancing overall performance.


